Recent multimodal large language models (MLLMs) have shifted image quality assessment (IQA) from black-box quality scoring toward explainable quality analysis. However, existing datasets and benchmarks are not specifically designed for user-generated content (UGC) distortions, which arise from real-world capture, processing, and sharing pipelines. They also lack a unified framework for detailed IQA.
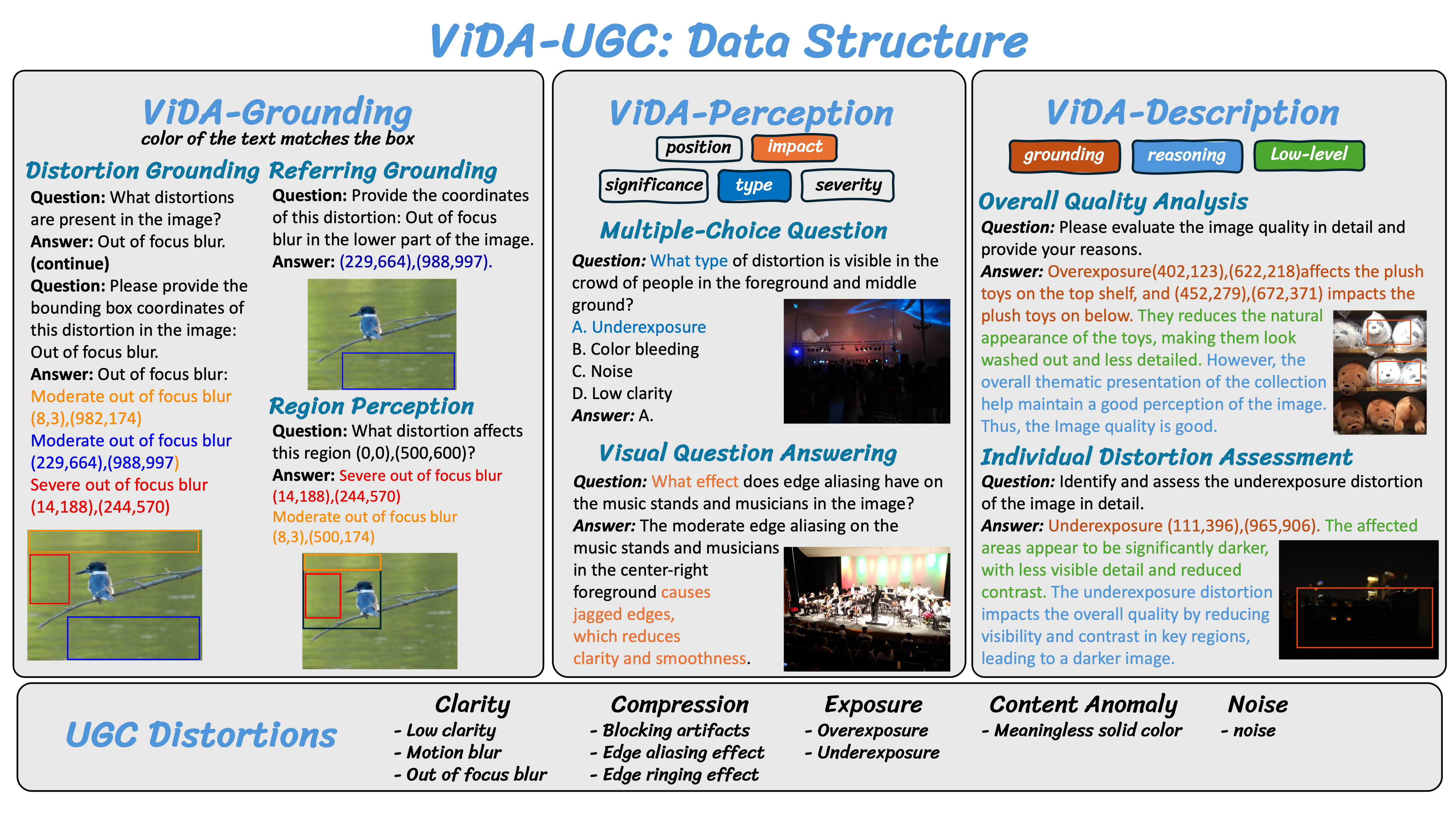
In this study, we propose detailed IQA for UGC images, formulated around three core abilities: Grounding (A1), Perception (A2), and Description (A3). To support these abilities, we establish the first large-scale Visual Distortion Assessment Instruction Tuning Dataset for UGC images, named ViDA-UGC, containing 11,534 images, 36K distortion bounding boxes, and 534K instruction tuning data. This dataset is built through a distortion-oriented pipeline combining human subject annotation with Grounding-Perception-Guided Controlled Chain-of-Thought (GPGC CoT) prompting, which guides GPT-4o to progressively identify, analyze, and reason about UGC distortions along an explicit distortion evidence chain.
We further select and verify a subset of ViDA-UGC with a professional team to build ViDA-UGC-Bench, the first UGC distortion assessment benchmark covering all three abilities. Experimental results show that ViDA-UGC fine-tuning consistently enhances grounding, perception, and description across Qwen-VL and InternVL series, while GPGC CoT prompting further improves quality descriptions without fine-tuning, with the best-tuned models even surpassing GPT-4o. ViDA-UGC-Bench further reveals that current MLLMs remain limited in distortion assessment for detailed IQA. The dataset and code will be released publicly.
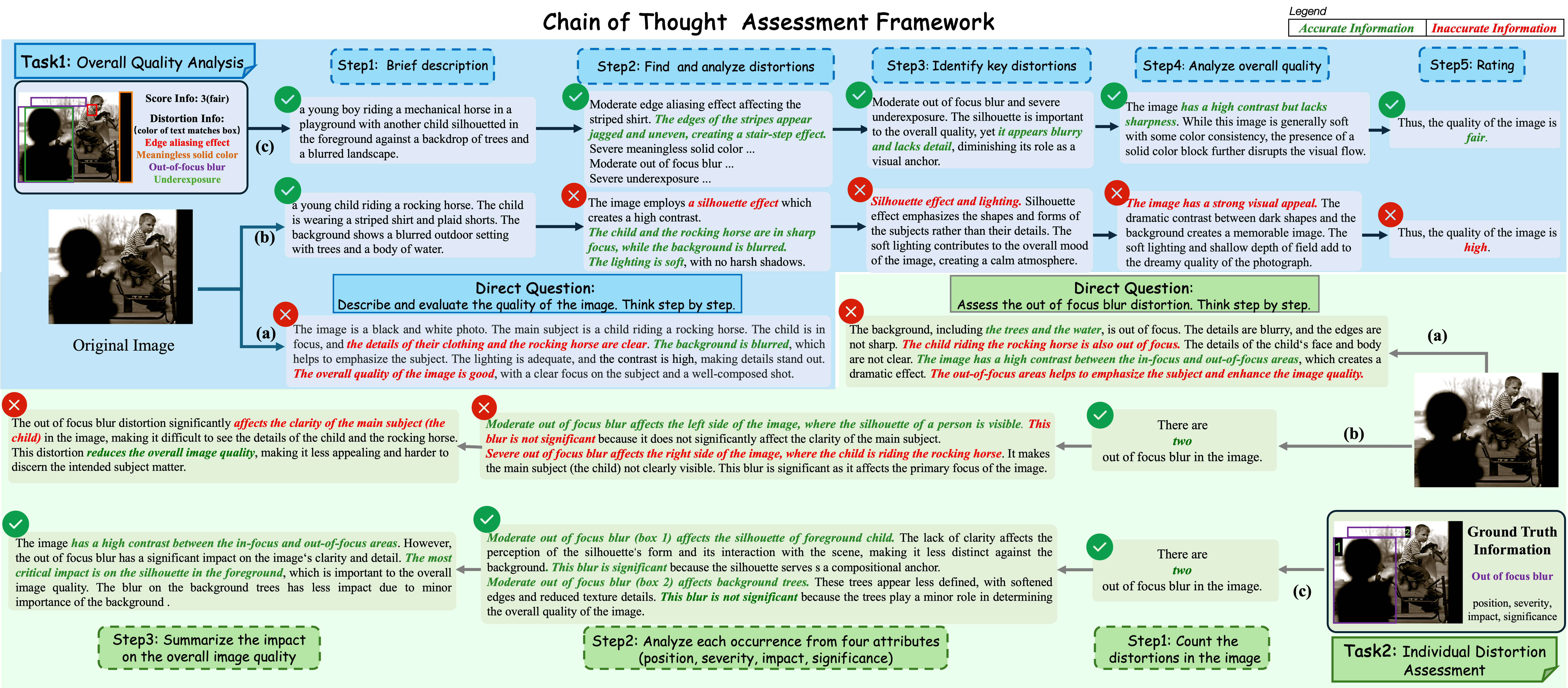
Overview of our GPGC CoT prompting. Direct CoT prompting often produces inaccurate low-level observations and superficial reasoning, while step-wise controlled CoT improves reasoning structure but can still hallucinate distortion evidence. GPGC CoT incorporates human expertise and ground-truth distortion annotations to guide reliable reasoning and accurate quality prediction along an explicit distortion-to-judgment evidence chain.
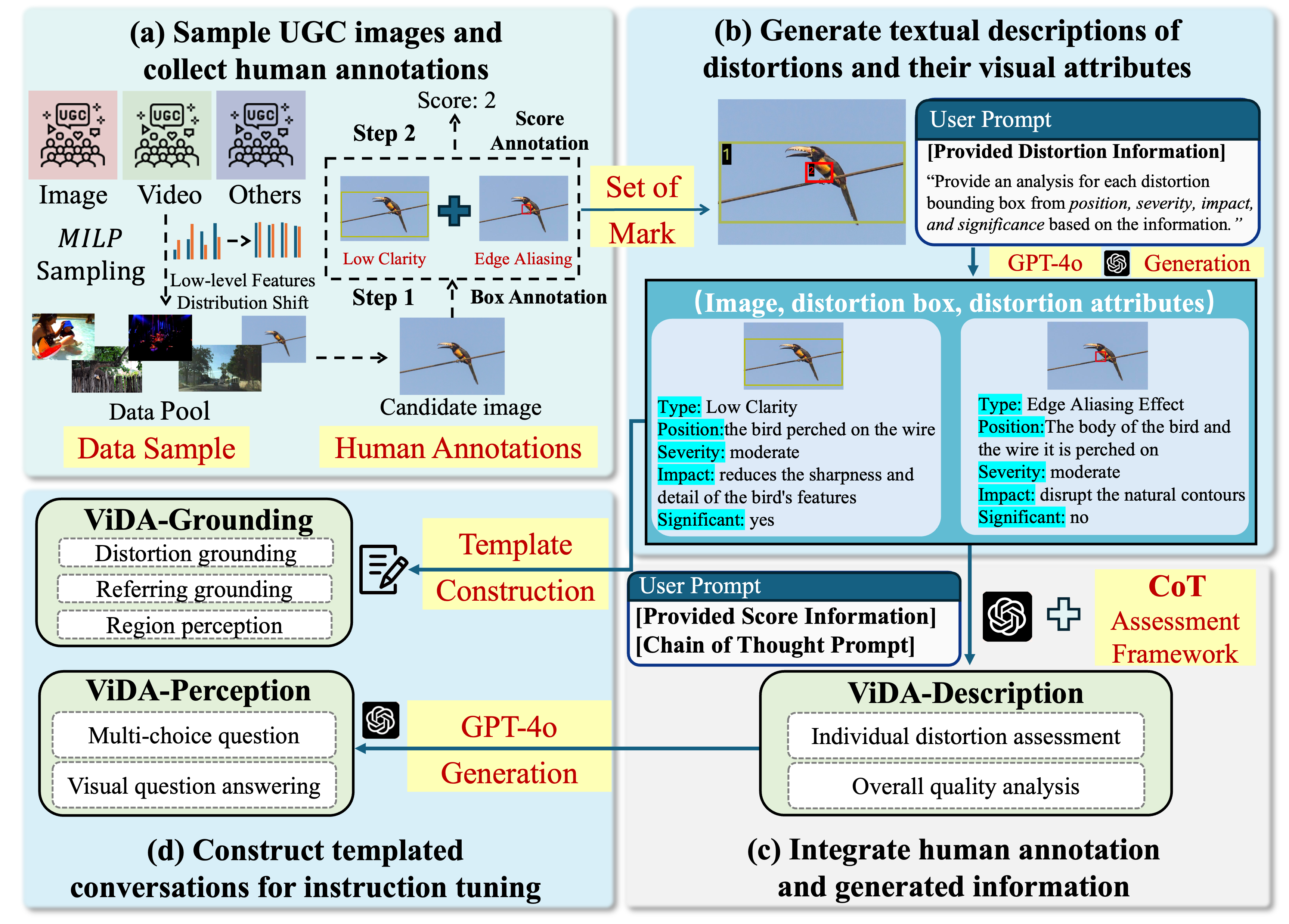
Overview of the ViDA-UGC construction pipeline. The pipeline first samples representative UGC images through a MILP strategy and collects human annotations of distortion regions and quality scores. It then injects IQA expertise into GPT-4o prompts to generate distortion attributes, integrates human annotations and distortion evidence into GPGC CoT prompting to produce controlled reasoning descriptions, and finally organizes the raw data into ViDA-Grounding, ViDA-Perception, and ViDA-Description instruction-tuning subsets.

To rigorously evaluate detailed IQA in the UGC setting, we introduce ViDA-UGC-Bench, the benchmark counterpart to ViDA-UGC. It contains 476 images with distortion triplet samples, 476 overall quality analyses from ViDA-Description, 2,567 multiple-choice questions from ViDA-Perception, and 3,106 grounding samples from ViDA-Grounding. A professional team verifies the low-level distortion information and question-answer pairs to reduce GPT-4o bias. The benchmark covers all ten UGC distortion categories and evaluates MLLMs across grounding, perception, and description abilities.
| Model | Variant | Response Rate | Acc0.5 | mIoU |
|---|---|---|---|---|
| Qwen-VL-Chat | Baseline | 1.00 | 32.4 | 37.3 |
| ViDA | 1.00 | 41.3(+8.9) | 43.4(+6.1) | |
| Qwen2-VL-7B | Baseline | 0.79 | 24.9 | 29.8 |
| ViDA | 0.99 | 42.1(+17.2) | 45.2(+15.4) | |
| InternVL2.5-8B | Baseline | 0.98 | 29.0 | 37.0 |
| ViDA | 1.00 | 43.3(+14.3) | 46.4(+9.4) | |
| InternVL3-8B | Baseline | 0.95 | 25.8 | 33.5 |
| ViDA | 1.00 | 44.2(+18.4) | 47.0(+13.5) |
Referring grounding results for baseline and ViDA-UGC-tuned MLLMs. Response rate is the fraction of valid box outputs; the best result is in bold and the largest gain is in red.
| Type | Method | DES mAP | DG mAP | RP mAP |
|---|---|---|---|---|
| Detector | TOOD | - | 29.2 | 36.2 |
| Co-DETR | - | 31.4 | 35.8 | |
| Grounding DINO | - | 37.1 | 42.2 | |
| MLLM | InternVL3-8B-ViDA | 17.4 | 19.7 | 30.4 |
| InternVL2.5-8B-ViDA | 15.9 | 20.0 | 32.3 | |
| Qwen2-VL-7B-ViDA | 17.9 | 17.7 | 29.4 | |
| Qwen-VL-Chat-ViDA | 15.5 | 16.8 | 27.1 |
Distortion grounding and region perception results for fine-tuned detectors and ViDA-UGC-tuned MLLMs. DES extracts boxes from quality descriptions, DG performs direct distortion grounding, and RP denotes region perception.
| Model (variant) | Training Dataset | Type | Concern | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|
| Yes-or-No | What | How | Distortion | Other | I-C Distortion | I-C Other | |||
| Qwen-VL-Chat | no (Baseline) | 56.00% | 58.63% | 54.77% | 50.78% | 61.57% | 53.62% | 62.45% | 56.39% |
| Q-Instruct | 78.36% | 74.56% | 61.05% | 70.43% | 67.59% | 74.34% | 77.14% | 71.51% | |
| ViDA-UGC | 77.09% | 78.32% | 66.53% | 78.60% | 65.97% | 79.93% | 71.02% | 73.98% | |
| Qwen2-VL-7B | no (Baseline) | 83.82% | 82.74% | 64.71% | 75.49% | 77.08% | 75.66% | 82.86% | 77.19% |
| Q-Instruct | 84.00% | 80.97% | 65.31% | 75.68% | 75.69% | 77.63% | 80.82% | 76.92% | |
| ViDA-UGC | 82.55% | 86.95% | 72.62% | 87.16% | 70.83% | 85.20% | 78.37% | 80.60% | |
| InternVL2.5-8B | no (Baseline) | 78.91% | 77.21% | 65.52% | 69.07% | 76.85% | 70.07% | 84.08% | 73.98% |
| Q-Instruct | 81.64% | 83.63% | 64.10% | 76.65% | 72.00% | 76.64% | 83.67% | 76.45% | |
| ViDA-UGC | 81.45% | 85.18% | 71.60% | 87.74% | 66.20% | 84.54% | 78.37% | 79.33% | |
| InternVL3-8B | no (Baseline) | 78.91% | 76.99% | 67.95% | 70.43% | 75.93% | 71.38% | 85.71% | 74.72% |
| Q-Instruct | 76.73% | 79.20% | 63.69% | 70.43% | 70.37% | 75.99% | 80.41% | 73.18% | |
| ViDA-UGC | 80.00% | 85.40% | 66.53% | 82.49% | 70.37% | 79.93% | 74.69% | 77.19% | |
| GPT-4o | no (Zero-shot) | 83.59% | 82.40% | 71.81% | 75.14% | 78.76% | 78.10% | 85.00% | 78.60% |
Comparison of the perception ability between baseline MLLMs, Q-Instruct-tuned versions, and ViDA-UGC-tuned versions on Q-Bench (LLVisionQA-dev). For each baseline model, the highest score is highlighted in bold.
| Model (variant) | Training Dataset | Dimension | Concern | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Clarity | Compress | Exposure | Content | Noise | Type | Position | Severity | Significance | |||
| Qwen-VL-Chat | no (Baseline) | 41.54% | 18.71% | 46.09% | 50.85% | 13.03% | 31.91% | 37.83% | 31.72% | 36.64% | 34.84% |
| Q-Instruct | 30.27% | 39.94% | 50.22% | 47.46% | 14.23% | 28.50% | 35.79% | 31.72% | 47.12% | 35.88% | |
| ViDA-UGC | 66.89% | 69.34% | 58.71% | 66.10% | 46.86% | 60.27% | 54.44% | 74.37% | 69.49% | 63.34% | |
| Qwen2-VL-7B | no (Baseline) | 51.90% | 52.83% | 43.75% | 47.46% | 17.15% | 43.43% | 43.53% | 51.26% | 54.15% | 47.53% |
| Q-Instruct | 43.17% | 55.82% | 39.06% | 45.76% | 20.92% | 34.12% | 42.00% | 51.47% | 52.08% | 44.14% | |
| ViDA-UGC | 69.45% | 84.12% | 69.64% | 86.44% | 46.86% | 76.37% | 61.17% | 80.46% | 72.20% | 71.45% | |
| InternVL2.5-8B | no (Baseline) | 39.75% | 53.77% | 44.64% | 55.93% | 18.41% | 37.08% | 43.78% | 44.96% | 49.04% | 43.51% |
| Q-Instruct | 34.25% | 59.75% | 41.96% | 61.86% | 32.22% | 29.99% | 38.32% | 68.07% | 45.53% | 43.40% | |
| ViDA-UGC | 73.15% | 85.69% | 71.43% | 84.75% | 60.25% | 81.24% | 62.06% | 82.14% | 78.27% | 74.80% | |
| InternVL3-8B | no (Baseline) | 50.76% | 52.52% | 46.65% | 55.93% | 12.13% | 43.57% | 47.08% | 47.06% | 52.08% | 47.37% |
| Q-Instruct | 31.50% | 55.97% | 38.84% | 52.54% | 28.03% | 29.10% | 34.90% | 53.15% | 47.28% | 39.77% | |
| ViDA-UGC | 71.35% | 87.74% | 70.31% | 83.90% | 46.03% | 82.87% | 61.80% | 78.15% | 72.52% | 73.00% | |
| GPT-4o | no (Zero-shot) | 54.93% | 51.26% | 72.54% | 58.47% | 26.36% | 46.38% | 60.28% | 53.57% | 59.58% | 55.20% |
Comparison of the perception ability between baseline MLLMs, Q-Instruct-tuned versions, and ViDA-UGC-tuned versions on ViDA-UGC-Bench. Compress denotes the compression dimension, and content denotes the content-anomaly dimension. For each baseline model, the highest score is highlighted in bold.
| Model (variant) | Training Dataset | Q-Bench | ViDA-UGC-Bench | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Completeness | Precision | Relevance | Overall | Completeness | Precision | Reasoning | Overall | ||
| Qwen-VL-Chat | no (Baseline)* | 0.72 | 0.53 | 1.86 | 3.11 | 0.20 | 0.58 | 1.56 | 2.34 |
| no (Baseline)† | 0.78 | 0.55 | 1.99 | 3.32 | 0.50 | 0.77 | 2.13 | 3.40 | |
| Q-Instruct* | 0.97 | 0.76 | 1.95 | 3.68 | 0.58 | 0.93 | 1.98 | 3.49 | |
| ViDA-UGC† | 1.07 | 0.74 | 1.99 | 3.80 | 1.33 | 1.14 | 2.89 | 5.36 | |
| Qwen2-VL-7B | no (Baseline)* | 1.30 | 1.06 | 2.00 | 4.36 | 0.70 | 0.73 | 2.78 | 4.21 |
| no (Baseline)† | 1.36 | 1.28 | 2.00 | 4.64 | 0.74 | 0.92 | 2.88 | 4.54 | |
| Q-Instruct* | 1.15 | 1.35 | 2.00 | 4.50 | 0.69 | 1.14 | 1.78 | 3.61 | |
| ViDA-UGC† | 1.40 | 1.30 | 2.00 | 4.70 | 1.49 | 1.34 | 2.95 | 5.78 | |
| InternVL2.5-8B | no (Baseline)* | 0.96 | 0.72 | 1.83 | 3.51 | 0.74 | 0.74 | 2.76 | 4.24 |
| no (Baseline)† | 1.15 | 1.03 | 1.94 | 4.12 | 0.75 | 1.25 | 2.90 | 4.90 | |
| Q-Instruct* | 0.97 | 1.22 | 1.93 | 4.12 | 0.63 | 1.28 | 1.63 | 3.54 | |
| ViDA-UGC† | 1.22 | 1.23 | 1.99 | 4.44 | 1.46 | 1.32 | 2.94 | 5.72 | |
| InternVL3-8B | no (Baseline)* | 1.10 | 0.93 | 1.86 | 3.89 | 0.93 | 0.96 | 2.95 | 4.84 |
| no (Baseline)† | 1.27 | 1.34 | 2.00 | 4.61 | 0.96 | 1.28 | 2.98 | 5.22 | |
| Q-Instruct* | 0.98 | 1.32 | 1.95 | 4.25 | 0.64 | 1.25 | 1.63 | 3.52 | |
| ViDA-UGC† | 1.34 | 1.35 | 1.99 | 4.68 | 1.51 | 1.36 | 3.00 | 5.87 | |
Description comparison among baseline MLLMs, Q-Instruct-tuned versions, and ViDA-UGC-tuned versions. Results with * are obtained using the Q-Instruct prompt ('Describe and evaluate the quality of the image. Think step by step.'), and those with † use our proposed GPGC CoT prompting. For each baseline model, the best are highlighted in bold and second-best scores are highlighted in blue.
@misc{liao2025vidaugcdetailedimagequality,
title={ViDA-UGC: Detailed Image Quality Analysis via Visual Distortion Assessment for User-Generated Content},
author={Wenjie Liao and Jieyu Yuan and Yifang Xu and Chunle Guo and Jihong Li and Zilong Zhang and Jiachen Fu and Haotian Fan and Chongyi Li},
year={2025},
eprint={2508.12605},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.12605},
}
Feel free to contact us at:
liaowenjie@mail.nankai.edu.cn
jieyuyuan.cn@gmail.com
lichongyi@nankai.edu.cn
We are pleased to announce that we have successfully organized the Detailed Image Quality Assessment Challenge in MIPI 2025 using the ViDA-UGC dataset. For more information, please visit the challenge page (https://www.codabench.org/competitions/8156/#/pages-tab) and the official MIPI 2025 website (https://mipi-challenge.org/MIPI2025).